Ceph 是一个符合POSIX、开源的分布式存储系统;其具备了极好的可靠性、统一性、鲁棒性;经过近几年的发展,Ceph 开辟了一个全新的数据存储途径。Ceph 具备了企业级存储的分布式、可大规模扩展、没有单点故障等特点,越来越受到人们青睐;以下记录了 Ceph 的相关学习笔记。
一、 Ceph Quick Start 1.1、安装前准备 本文以 Centos 7 3.10 内核为基础环境,节点为 4 台 Vagrant 虚拟机;Ceph 版本为 Jewel.
首先需要一台部署节点,这里使用的是宿主机;在部署节点上需要安装一些部署工具,如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 cat << EOF >> /etc/yum.repos.d/ceph.repo [ceph-noarch] name=Ceph noarch packages baseurl=https://download.ceph.com/rpm-jewel/el7/noarch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc EOF
同时,ceph-deploy 工具需要使用 ssh 来自动化部署 Ceph 各个组件,因此需要保证部署节点能够免密码登录待部署节点;最后,待部署节点最好加入到部署节点的 hosts 中,方便使用域名(某些地方强制)连接管理
1.2、校对时钟 由于 Ceph 采用 Paxos 算法保证数据一致性,所以安装前需要先保证各个节点时钟同步
1 2 3 4
1.3、创建集群配置 ceph-deploy 工具部署集群前需要创建一些集群配置信息,其保存在 ceph.conf 文件中,这个文件未来将会被复制到每个节点的 /etc/ceph/ceph.conf
1 2 3 4 5 6 mkdir ceph-cluster && cd ceph-clusterecho "osd pool default size = 3" >> ceph.conf
1.4、创建集群 创建集群使用 ceph-deploy 工具即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 mkdir /datachown -R ceph:ceph /datachmod +r /etc/ceph/ceph.client.admin.keyring
执行 ceph health 命令后应当返回 HEALTH_OK;如出现 HEALTH_WARN clock skew detected on mon.docker2; Monitor clock skew detected,说明时钟不同步,手动同步时钟稍等片刻后即可;其他错误可以通过如下命令重置集群重新部署
1 2 3 ceph-deploy purge {ceph-node} [{ceph-node}]
更多细节,如防火墙、SELinux配置等请参考 官方文档
1.5、其他组件创建 1 2 3 4 5 6 7 8 9 echo "public network = 192.168.1.0/24" >> ceph.conf
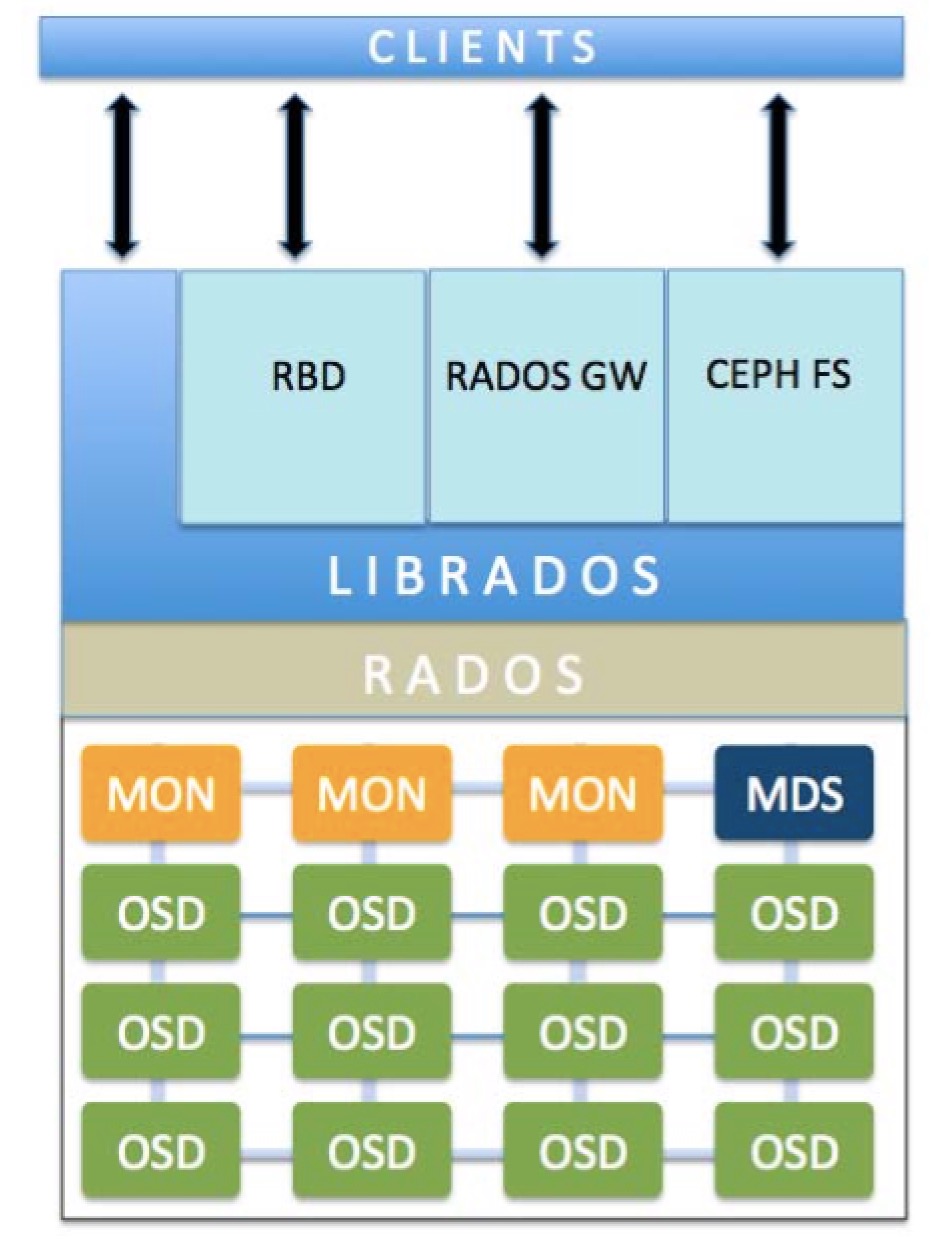
二、Ceph 组件及测试 2.1、Ceph 架构图 以下图片(摘自网络)展示了基本的 Ceph 架构
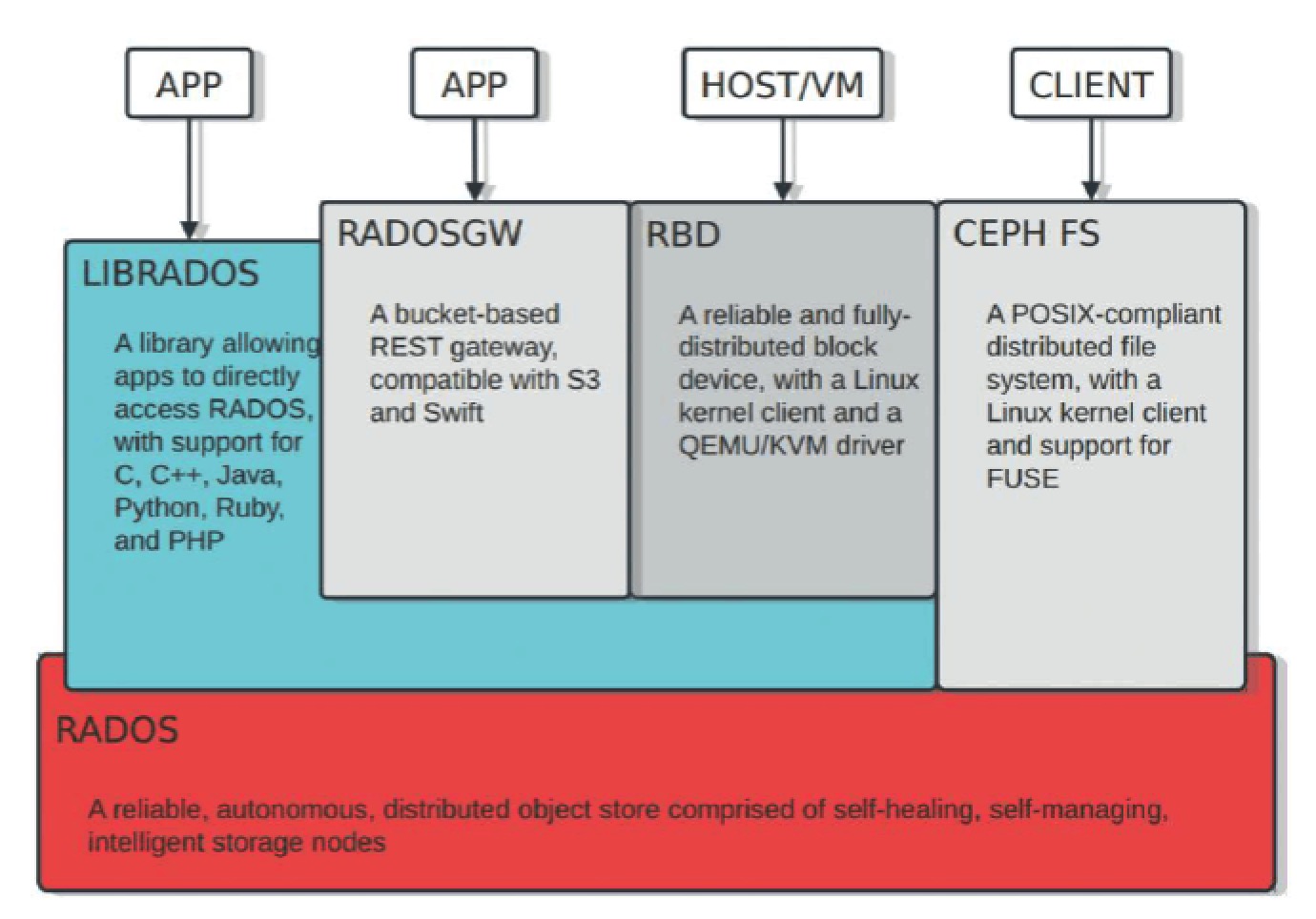
OSD: Ceph 实际存储数据单元被称为 OSD,OSD 可以使用某个物理机的目录、磁盘设备,甚至是 RAID 阵列; MON: 在 OSD 之上则分布着多个 MON(monitor),Ceph 集群内组件的状态信息等被维护成一个个 map,而 MON 则负责维护集群所有组件 map 信息,各个集群内组件心跳请求 MON 以确保其 map 保持最新状态;当集群发生故障时,Ceph 将采用 Paxos 算法保证数据一致性,这其中仲裁等主要由 MON 完成,所以 MON 节点建议最少为 3 个,并且为奇数以防止脑裂情况的发生; MDS: Ceph 本身使用对象形式存储数据,而对于外部文件系统访问支持则提供了上层的 CephFS 接口;CephFS 作为文件系统接口则需要一些元数据,这些原数据就存放在 MDS 中;目前 Ceph 只支持单个 MDS 工作,但是可以通过设置 MDS 副本,以保证 MDS 的可靠性 RADOS: RADOS 全称 Reliable Autonomic Distributed Object Store,即可靠分布式对象存储;其作为在整个 Ceph 集群核心基础设施,向外部提供基本的数据操作 librados: 为了支持私有云等程序调用,Ceph 提供了 C 实现的 API 库 librados,librados 可以支持主流编程语言直接调用,沟通 RADOS 完成数据存取等操作 RBD: RDB 个人理解是一个命令行工具,一般位于宿主机上,通过该工具可以直接跟 librados 交互,实现创建存储对象,格式化 Ceph 块设备等操作 RADOS GW: 从名字可以看出来,这个组件是一个代理网关,通过 RADOS GW 可以将 RADOS 响应转化为 HTTP 响应,同样可以将外部 HTTP 请求转化为 RADOS 调用;RADOS GW 主要提供了三大功能: 兼容 S3 接口、兼容 Swift 接口、提供管理 RestFul API 下图(摘自网络)从应用角度描述了 Ceph 架构
2.2、对象存储测试 此处直接上代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 dd if =/dev/zero of=test bs=1G count=1test --pool=datals rm test-file
2.3、块设备测试 官方文档中提示,使用 rdb 的客户端不建议与 OSD 等节点在同一台机器上
You may use a virtual machine for your ceph-client node, but do not execute the following procedures on the same physical node as your Ceph Storage Cluster nodes (unless you use a VM). See FAQ for details.
这里从第四台虚拟机上执行操作,首先安装所需客户端工具
1 2 3
然后创建块设备
1 2 3 4
在上面的 map 映射操作时,可能出现如下错误
1 RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable"
查看系统日志可以看到如下输出
1 2 3 4 ➜ ~ dmesg | tail
问题原因: 在 Ceph 高版本进行 map image 时,默认 Ceph 在创建 image(上文 data)时会增加许多 features,这些 features 需要内核支持,在 Centos7 的内核上支持有限,所以需要手动关掉一些 features
首先使用 rbd info data 命令列出创建的 image 的 features
1 2 3 4 5 6 7 rbd image 'data' :in 2560 objects
在 features 中我们可以看到默认开启了很多:
layering: 支持分层 striping: 支持条带化 v2 exclusive-lock: 支持独占锁 object-map: 支持对象映射(依赖 exclusive-lock) fast-diff: 快速计算差异(依赖 object-map) deep-flatten: 支持快照扁平化操作 journaling: 支持记录 IO 操作(依赖独占锁) 而实际上 Centos 7 的 3.10 内核只支持 layering… 所以我们要手动关闭一些 features,然后重新 map;如果想要一劳永逸,可以在 ceph.conf 中加入 rbd_default_features = 1 来设置默认 features(数值仅是 layering 对应的 bit 码所对应的整数值)。
1 2 3 4 5 6 disable data exclusive-lock, object-map, fast-diff, deep-flatten
最后我们便可以格式化正常挂载这个设备了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ➜ ~ mkfs.xfs /dev/rbd0log =internal log bsize=4096 blocks=2560, version=2mkdir test1dd if =/dev/zero of=test1/test-file bs=1G count=1ls test1
2.4、CephFS 测试 在测试 CephFS 之前需要先创建两个存储池和一个 fs,创建存储池要指定 PG 数量
1 2 3 ceph osd pool create cephfs_data 32
PG 概念:
当 Ceph 集群接收到存储请求时,Ceph 会将其分散到各个 PG 中,PG 是一组对象的逻辑集合;根据 Ceph 存储池的复制级别,每个 PG的数据会被复制并分发到集群的多个 OSD 上;一般来说增加 PG 数量能降低 OSD 负载,一般每个 OSD 大约分配 50 ~ 100 PG,关于 PG 数量一般遵循以下公式
集群 PG 总数 = (OSD 总数 * 100) / 数据最大副本数 单个存储池 PG 数 = (OSD 总数 * 100) / 数据最大副本数 /存储池数 注意,PG 最终结果应当为最接近以上计算公式的 2 的 N 次幂(向上取值);如我的虚拟机环境每个存储池 PG 数 = 3(OSD) * 100 / 3(副本) / 5(大约 5 个存储池) = 20,向上取 2 的 N 次幂 为 32
挂载 CephFS 一般有两种方式,一种是使用内核驱动挂载,一种是使用 ceph-fuse 用户空间挂载;内核方式挂载需要提取 Ceph 管理 key,如下
1 2 3 4 5 6 7 8 9 10 echo "AQB37CZZblBkDRAAUrIrRGsHj/NqdKmVlMQ7ww==" > ceph-keymkdir test2dd if =/dev/zero of=test2/testFs bs=1G count=1
使用 ceph-fuse 用户空间挂载方式比较简单,但需要先安装 ceph-fuse 软件包
1 2 3 4 5 6 7 8 9 10 mkdir test3dd if =/dev/zero of=test3/testFs bs=1G count=1
2.5、对象网关测试 对象网关在 1.5、其他组件创建 部分已经做了创建(RGW),此时直接访问 http://ceph-node-ip:7480 返回如下
1 2 3 4 5 6 7 <ListAllMyBucketsResult xmlns ="http://s3.amazonaws.com/doc/2006-03-01/" > <Owner > <ID > anonymous</ID > <DisplayName /> </Owner > <Buckets /> </ListAllMyBucketsResult >
这就说明网关已经 ok,由于手里没有能读写测试工具,这里暂不做过多说明
本文主要参考 Ceph 官方文档 Quick Start 部分,如有其它未说明到的细节可从官方文档获取